AlgorithmenGrundlagenLogikSummenregeln 🐝Logarithmus RegelnGeometrische ReiheRechenoperationen + ZifferstellenSchleifeninvarianteLaufzeitanalyse von Algorithmen ⏳Laufzeit von CodeElementare ZuweisungenMaster-Theorem (Divide-And-Conquer) 👑Landau Notation 🅾️$f \in o(g)$$f \in O(g)$$f \in \Omega(g)$$f \in \Theta(g)$$f \in \omega(g)$Landau Notation FolgerungenBekannte OrdnungenO(log n)O(n)O(n log n)O(n2)O(nk)SortierenBubble Sort🛁Insertion Sort🃏Selection SortMerge SortQuick Sort ⏩Quick SelectBFPRTHeap SortSchranken des SortierproblemsCounting Sort 🧮Radix SortSuchen 🔍Lineare SucheBinäre SucheDatenstrukturenVergleichFIFO vs LIFODynamisches ArrayPower dictionaryPrioritätswartschlangeHeapsBinärer HeapBinomial HeapHollow HeapFibonacci HeapBäumeBinäre Suchbäume 🌲AVL-Bäume (Fibonacci Bäume) 🌴Hash Tabelle 🌿Grundlagen des HashingPerfekte Hashfunktion 👌KollisisionswahrscheinlichkeitOffenes Hashing mit geschlossener Adressierung ⛓Geschlossenes Hashing mit offener AdressierungPolynomielles SondierenDoppelhashingSuchen nach LöschenUniverselles HashingGraphen 📈AllgemeinesDarstellungAdjazenzmatrixAdjazenzlisteGraph-DurchlaufBreitendurchlaufTiefendurchlaufTopologisches SortierenGraph Isomorphismus ProbelmKosaraju’s AlgorithmusBellman-Ford AlgorithmusDijkstra AlgorithmusJohnson’s APSP AlgorithmFloyd-Warshall AlgorithmusMinimale SpannbäumeGrundlagenKruskal AlgorithmusPrim AlgorithmusÜbungenLaufzeiten bestimmenBeweise: $g \notin O(f)$Beweise: ${n\choose k} \in \Theta(n^k)$Beweise: $log(n) \in O(n^k)$Anzahl der FunktionsaufrufeWie kann man den Katasube-Ofman Algorithmus verallgemeinern?Wurf mit Bällen auf EimerDijkstra mit negativen KantenPseudocodeSorting AlgorithmsInsertion SortSelection SortMerge SortQuick SortHeap SortCounting SortRadix SortDatenstrukturenVerkettete ListeDoppelt verkettete ListeStackQueueBinärer HeapGraphenTopologisches SortierenDFSBFSBellman-FordDijkstraKruskalPrim
Algorithmen
Grundlagen
Logik
- bedeutet, dass die Behauptung links des Pfeils nur gilt, wenn (if and only if) die Behauptung rechts des Pfeils gilt
Summenregeln 🐝
Logarithmus Regeln
Geometrische Reihe
- Für gilt:
- Ableiten und mit multiplizieren:
- Für gilt
Rechenoperationen + Zifferstellen
- : Ziffern, Grundoperationen
- : Ziffern, Grundoperationen
- Ziffern Grundoperationen
- =>
- =>
- =>
- Zahl plus Zahl
Schleifeninvariante
Verträge bestehen aus
- Vorbedingungen: Zusicherungen, die beim Aufruf des Algorithmus einzuhalten sind
- Nachbedingungen: Zusicherungen, die am Ende des Algorithmus gelten
- Invarianten: Schleifeninvarianten müssen vor/nach jeder Ausführung eines Schleifenkörpers gelten
The loop invariant is a single condition or set of conditions that the algorithm maintains at the beginning, the end, and during each iteration of its execution
The loop invariant for selection sort is that the elements of the newly sorted array up to the current index,
A[0..i]will contain the i smallest elements of our original input,A[0..n-1]. They will also be in sorted order.The loop invariant for insertion sort states that all elements up to the current index,
A[0..i], make up a sorted permutation of the elements originally found inA[0..i]before we began sorting.
Laufzeitanalyse von Algorithmen ⏳
Laufzeit von Code
Elementare Zuweisungen
- Variablendeklaration:
String str; - Initialisierung und Zuweisung:
int i = j + 3; - Vergleiche:
if (j == 7)
Sequenzen von Anweisungen
- Laufzeiten für Sequenzen von Anweisungen werden addiert
- Verzweigungen werden addiert , z.B. bedingte Blöcke (
if) oder Fallunterscheidungen (switch) - Schleifen werden multipliziert
Master-Theorem (Divide-And-Conquer) 👑
- mit gilt
Landau Notation 🅾️
- wächst langsamer als
- wächst nicht wesentlich schneller als
- Asymptotisch untere Schranke
- Asymptotisch scharfe Schranke, sowohl , als auch
- Asymptotisch dominant
Landau Notation Folgerungen
Bekannte Ordnungen
O(log n)
- Since it takes linear time just to read the input, these situations tend to arise in a model of computation where the input can be “queried” indirectly rather than read completely, and the goal is to minimize the amount of querying that must be done
- E.g. binary search algorithm
O(n)
One basic way to get an algorithm with this running time is to process the input in a single pass, spending a constant amount of time on each item of input encountered
E.g. computing the maximum, merging two sorted lists into one sorted list
max = arr[0]for i in range(1,len(arr)):if arr[i] > max:max = arr[i]return max
O(n log n)
- It is the running time of any algorithm that splits its input into two equal-sized pieces, solves each piece recursively, and then combines the two solutions in linear time
O(n2)
- Quadratic time arises naturally from a pair of nested loops
O(nk)
- We obtain a running time of O(nk) for any constant k when we search over all subsets of size k
Sortieren
Bubble Sort🛁
Idee: Vergleiche Paare von benachbarten Schlüsseln und tausche, wenn linker Schlüssel größer ist als rechter
Maximum wandert nach hinten
xxxxxxxxxxint n = a.length;for i in range(0, i < n):for j in range (0, j < n-i-1):if (a[j] > a[j+1]):swap(a,j,j+1)Variable i: wieviele Elemnte am Ende sind schon soritiert
Variable j: Nachbarschaftsvergleiche auf dem unsortierten "Rest"
🚢 Anzahl der Vergleiche :
🍓 Anzahl der Vertauschungen:
- Best Case: 0 Swaps
- Worst Case: Swaps
- Average Case: Swaps
Insertion Sort🃏
🔑 Schlüssel: Zahlen die sortiert werden sollen
Vergleichbar mit dem Sortieren von Spielkarten auf der Hand
xxxxxxxxxxfor i in range(1, len(arr)):key = arr[i]j = i-1while j >=0 and key < arr[j] :arr[j+1] = arr[j]j -= 1arr[j+1] = keyist die "aktuelle" Karte die eingeordnet werden muss
Algorithmus Kosten Anzahl for i = 2 to A.length key = A[i] j = i - 1 while j > 0 and A[j] > key A[j + 1] = A[j] j = j - 1 A[j + 1] = key = Anzahl der Ausführungen des while loop
Der Test für for und while loops wird einmal öfter ausgeführt, als der Inhalt der Schleife
Anzahl der Vergleiche:
Best Case: bei sortierter Folge
Average und Worst Case:
Anzahl Verschiebeoperationen:
- Worst Case:
- Average Case:
Selection Sort
Idee: Suche jeweils nächstes kleinstes Element
- Durchlaufe die Folge von links nach rechts mit einem Zeiger i
- Links von i sind die i-kleinsten Elemente sortiert
- Finde in der verbleibenden menge das kleinste Element und tausche es mit i. Dann erhöhe i um eins
- Tausche, falls linker Schlüssel größer ist als rechter
xxxxxxxxxxpublic void selectionSort(int[] a) {for(int i = 0; i < a.length-1; i++) {int min = i;for(int k = i+1; j < n; j++) {if(a[j] < a[min])min = j;}swap(a,i,min)}}Anzahl der Vertauschungen:
- Best Case, Worst Case, Average Case: Swaps
- Lineares Wachstum
Merge Sort
- Idee: Rekursives Zerlegen der Eingabefolge in zwei gleichlange Folgen. Sortieren der Teillisten. Zusammenfügen.
- Höhe des Merge Sort Binärbaums:
- Master Theorem:
- , da beim Merge Schritt die beiden Folgen jeweils einmal von links nach rechts durchgegangen werden und auch maximal viele Vergleiche benötigt.
- Zweiter Fall des Master Theorems:
Quick Sort ⏩
Idee: Optimierung von Merge Sort durch in-situ Sortieren
- Wähle ein Pivotelement
- Zerlegen in zwei Teilfolgen
- Rekursiven Sortieren
- Aufwand liegt im Divide Schritt, Merge Schritt ist lediglich Konkatenation
xdef quickSort(arr,low,high):if low < high:pi = partition(arr,low,high)quickSort(arr,low,pi-1)quickSort(arr,pi+1,high)def partition(arr,low,high):i = (low-1)pivot = arr[high] #could be randomfor j in range(low,high):if arr[j] <= pivot:i += 1arr[i], arr[j] = arr[j], arr[i]arr[i+1], arr[high] = arr[high], arr[i+1]return(i+1)Worst Case: Entarteter Baum
- Mit Master Theorem gilt
Average Case: Jede Länge ist gleich wahrscheinlich, im Durchschnitt ist als die Länge der größten Teilfolge
Pivot kann zufällig gewählt werden oder deterministisch mit dem Median-of-Medians Algorithmus in
Pivot: The value within the partitioning space that I want to find a position for
j: Scanning function
i: Remembers the last position that an element was placed in, that was less than the pivotx
Quick Select
BFPRT
Heap Sort
Binärbäume allgemein:
- Ein vollständiger Binärbaum mit hat Kanten
- Ein vollständiger Binärbaum mit hat Blätter
- Ein vollständiger Binärbaum ist ein voller Binärbaum (alle Knoten haben entweder 2 oder 0 Kinder) in dem alle Blätter die gleiche Tiefe haben
Heap Struktur: Binärbaum, der zwei Eigenschaften erfüllen muss
- Links-vollständig (letzte Ebene kann von rechts her unvollständig sein)
- Alle Vorgänger müssen größere (Max-Heap) oder kleinere (Min-Heap) Schlüssel haben als Nachfolger
"Beinahe-Max-Heap" (die Max-Heap-Eigenschaft ist bei der Wurzel verletzt)
Heapaufbau
- Benötigt Schritte
- Nur die wenigen Knoten weit oben im Baum brauchen Schritte
- Vollständiger Binärbaum mit Höhe hat Knoten
- Blätter () erfüllen immer die Heap Eigenschaft
- In der Ebene darüber gibt es Knoten, die maximal einen Schritt versickern. Und so weiter.
- Über alle Ebenen:
- Geometrische Reihe mit :
- Damit gilt mit : //beide Seiten +1
Heapify: Für jeden der Knoten (weil jeder mal Wurzel wird) wir gemacht
- Tauschen mit dem letzten Knoten
- Heapeigenschaft reparieren, Vertauschungen entlang eines Pfades im Baum, also
- Insgesamt:
Schranken des Sortierproblems
- Können Sortierprobleme besser als sein?
- Beim Sortieren muss eine Teilmenge aus der Menge aller Permutationen der Liste gefunden werden
- Der Ablauf eines nur auf Vergleichen basierenden Sortieralgorithmus kann durch einen Entscheidungsbaum dargestellt werden (Anzahl der Blätter ist )

- Ein Baum der Höhe hat minimal maximal Blätter
- Damit gilt
Counting Sort 🧮
- Schlüssel sind darstellbar als ganzzahlige Werte im Bereich
- Countingsort zählt, wie oft jeder dieser Werte in der Eingabe vorkommt. Diese Anzahlen speichert er in einem zusätzlichen Array mit Feldern ab. Mit Hilfe dieses Arrays wird anschließend für jeden Schlüsselwert die Zielposition in der Ausgabe berechnet
- Laufzeit- und Speicherkomplexität:
- Ungünstig bei großen
Radix Sort
- Sei mit und
- Soritere das Eingabe Array mal nach aufsteigender Signifikanz der Stellen (braucht stabilen Sortieralgorithmus)
- Laufzeit:
Suchen 🔍
Lineare Suche
- Jede Position eines Schlüssels ist gleichwahrscheinlich
- Durchschnittliche Anzahl an Vergleichen ist
Binäre Suche
- Suche einer Zahl in einer sortieren Zahlenfolge
xxxxxxxxxxl = 0r = n - 1while (l <= r) do m = round((r + l) / 2) if A[m] == x then return m if A[m] < x then l = m + 1 else r = m - 1return -1- Bei jedem Schleifendurchlauf halbiert sich der durchsuchte Bereich:
- Mit Master Theorem also
Datenstrukturen
Vergleich
| Baum | Sortierte Liste | Sortiertes Array | |
|---|---|---|---|
| Einfügen | |||
| Löschen | |||
| Zugriff |
FIFO vs LIFO
- FIFO: Queue - enqueue / dequeue
- LIFO: Stack - push / pop
Dynamisches Array
Array hat feste Größe
push()Opertation normalerweise , wenn Array noch Platz hat, wenn nicht muss ein neues Array mit doppelter Größe alloziert werden. In diesem Fall müssen alle Elemente in das neue Array kopiert werdenReallozieren des Arrays auf halbe Größe, wenn das Array nur noch zu befüllt ist.
pop()Operation also normal , mit ReallozierenAmortisierte Zeitanalyse für
push()undpop()- Jedes
push()undpop()bringen 5€ in die Kasse - 1€ für die normalen Kosten
- 4€ werden gespart
- Bei Reallokation sind dann also mindestens € im System
- weil der minimale Fall, dass eine Reallokation durchgeführt wird bei einem Füllgrad von stattfindet (halbierung des Array)
- Mit den € kann dann eine Reallokation bezahlt werden
- Die amortisierte Laufzeit ist also
- Jedes
Power dictionary
Prioritätswartschlange
Datenstruktur, die es erlaubt das kleinste Element schnell zu finden und aus der Menge zu entfernen
Mögliche Implementierung durch perfektem binären Baum, der die Heapeigenschaft erfüllt
Baum erfüllt (Min-)Heapeigenschaft falls für jeden Knoten ausser der Wurzel der Schlüsselwert größer ist als der Schlüsselwert des Vaterknotens
- MAKEQUEUE - O(1)
- UNION - O(n)
- MIN - O(1)
- EXTRACT-MIN - O(logn)
- INSERT - O(logn)
- DELETE - O(logn)
- DECREASE-KEY - O(logn)
Heaps
Binärer Heap
Binärbaum, fehlende Blätter rechts unten
Höhe
Änderungen nur entlag eines Pfades Wurzel-Blatt
insert()unddeleteMinbrauchenmin()dauertbuildHeap()braucht- Sei
- Sei Tiefe
- Aufrufe von
siftDown() - Kosten je
- Insgesamt:
Binomial Heap
Sammlung von Binomialbäumen, jeder Baum ist ein Heap
Es darf von jedem Grad nur einen Baum geben (merge trees of equal degree)
In einem Binärbaum von Grad hat die Wurzel Kinder
Der Baum hat Höhe
push()mit Worst Case , amortisiert in .push()muss meistens nur auf kurzen Bäumen stattfindendecreaseKey()mit Worst Case , da der Schlüssel eventuell bis nach ganz oben bubbeln musspopMin()mit Worst Case- Wurzelelement entnehmen
- Kinder auf höchste Ebene heben
- Bäume gleichen Grades mergen
Hollow Heap
Fibonacci Heap

Laufzeit
- MAKEQUEUE - O(1)
- UNION - O(1)
- MIN - O(1)
- EXTRACT-MIN - O(logn)
- INSERT - O(1)
- DELETE - O(logn)
- DECREASE-KEY - O(1 am.)
Bäume
- Baum in Array transformierbar
Binäre Suchbäume 🌲
Eine Binärer Suchbaum muss die Form , wenn im linken Teilbaum und im rechten Teilbaum liegt
⛔️ Min-Heap:
⛔️ Max-Heap:
Insert(key, value)
- Suche den Schlüssel key im Baum
- Falls key schon im Baum existiert, ersetze das vorherige Objekt
- Falls nicht, hält die Suche in einem Blatt oder inneren Knoten mit max. einem Nachfolger
- Füge einen neuen Knoten mit (key, value) als linker / rechter Folgeknoten bei diesem Knoten ein
Remove(key)
- Suche den Knoten Schlüssel key im Baum
- Falls key schon im Baum existiert, passiert nichts
- Falls ein Blatt ist, lösche den Zeiger darauf
- Falls ein innerer Knoten ist, finde den rechtesten Knoten ( ) im linken Teilbaum von . Tausche mit . Lösche dann den Blattknoten
Änderungen im baum mit
Suche der entsprechenden Position:
- Maximale Anzahl Vergleiche entspricht maximaler Pfadtiefe des Baumes
- Wenn die Höhe des Baumes, Komplexität der Suche
- Worst Case: , Best Case:
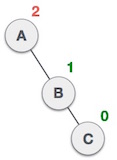
AVL-Bäume (Fibonacci Bäume) 🌴
- Binärer Suchbaum mit der Strukturbedingung: die Höhen der beiden Teilbäume unterscheiden sich höchstens um eins
- Das heißt, dass ein AVL Baum nicht maximal ausgeglichen sein muss, dafür ist er allerdings balanciert
- Um diese Bedingung aufrechtzuerhalten muss nach insert oder remove eventuell rebalanciert werden

Wie hoch kann ein ABL-Baum für eine gegebene Knotenanzahl maximal werden?
ist die minimale Anzahl Knoten eines AVL-Baums der Höhe
Für beliebigen minimal gefüllten AVL-Baum der Höhe gilt:
- Wurzel besitzt zwei Teilbäume
- Ein Teilbaum hat Höhe
- Der andere Teilbaum hat die Höhe
Ähnelt der Fibonacci Reihe. Deswegen
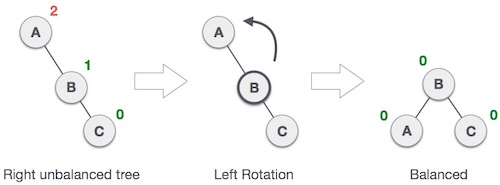
Links-links Rotation bei Einfügung in Teilbaum "rechts rechts"
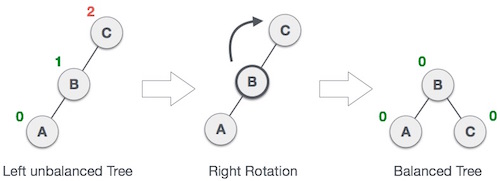
- Rechts-rechts Rotation bei Einfügung in Teilbaum "links links"
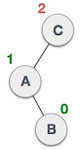
Links-rechts Rotation bei Einfügung in Teilbaum "links-rechts"
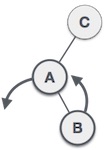
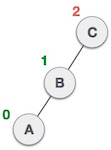
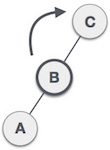
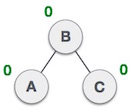
Rechts-links Rotation bei Einfügung in Teilbaum "rechts-links"
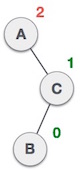
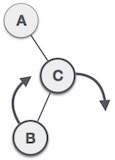
Rotationen brauchen konstante Zeit , Einfügen mit Rebalancierung also
Beim Löschen kann es passieren, dass man den ganzen Pfad entlag Rebalancierungen vornehmen muss, maximal also Rotationen. Löschen mit Rebalancierung also im Worst Case
Beinahe AVL-Baum: Nur an der Wurzel um debalanciert
Hash Tabelle 🌿
Grundlagen des Hashing
- Idee: Abbilden verschiedener Schlüssel auf dieselben Indexwerte. Kollisionen möglich
- Universum aller Schlüssel
- Menge der zu speichernden Schlüssel mit
- Hash-Tabelle mit
- ist die Hashfunktion, die den Indexwert berechnet
- ist der Belegungsfaktor
- Die Hashfunktion muss surjektiv sein
Perfekte Hashfunktion 👌
- Eine Hashfunktion ist perfekt wenn
- Eine Hashfunktion ist minimal wenn
Kollisisionswahrscheinlichkeit
- Wahrscheinlichkeit, dass es zu einer Kollision kommt ist
- Kollisionswahrscheinlichkeit bleibt konstant wenn quadratisch mit wächst
Offenes Hashing mit geschlossener Adressierung ⛓
- Speicherung der Schlüssel als verkettete Liste
- Worst Case: Suche mit , das heißt eine ganz lange verkette Liste mit allen Elementen
- Average Case: Suche mit unter der Annahme von Gleichverteilung
- Worst Case: Einfügen mit , immer am Anfang der Liste
- Worst Case: Löschen mit (Erklärung für Löschlaufzeit)
Geschlossenes Hashing mit offener Adressierung
Polynomielles Sondieren
- Für teste Hashadresse bis eine freie Adresse gefunden wurde
- Lineares Sondieren: , also
- Quadratisches Sondieren: , also
Doppelhashing
Nutzung zweier unabhängiger Hashfunktionen
- und
Sondierung mit
Suchen nach Löschen
- Offenes Hashing: Behälter suchen und Element aus Liste entfernen
- Geschlossenes Hashing: Behälter suchen und Zelle als gelöscht markieren. Notwendig, da evtl. bereits hinter dem gelöschten Element andere Elemente durch Sondieren eingefügt wurden
Universelles Hashing
- Sei
Heine endliche Menge an Hashfunktionen von nach .Hist universell falls für mit die Anzahl der HashfunktionenHmit höchstens ist. - Wahrscheinlichkeit einer Kollision mit höchstens
Graphen 📈
Allgemeines
- Menge der Knoten mit Knotenanzahl
- Menge der Kanten mit Kantenanzahl
- Grad eines Knoten ist die Anztahl der ein- und ausgehenden Kanten
- DAG: Quelle = Knoten mit Eingangsgrad Null, Senke = Knoten mit Ausgangsgrad Null
Darstellung
Adjazenzmatrix
- ist eine boolsche Matrix mit
- Entscheidung, ob in
- Platbedarf und Inititalisierung stets
- Anstelle von boolschen Werten können auch Zusatzinformationen (z.B. Kosten) in Matrix gespeichert werden
Adjazenzliste
- Entscheidung, ob im Average Case mit
- Platzbedarf und Initialisierung von
Graph-Durchlauf
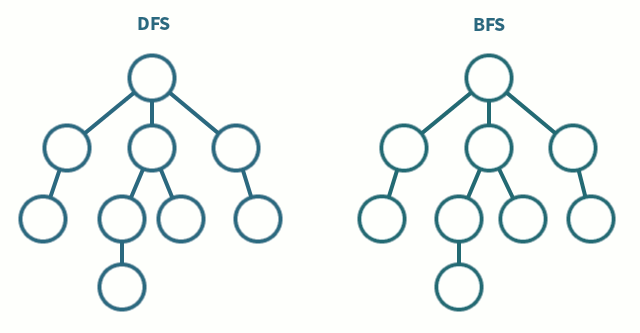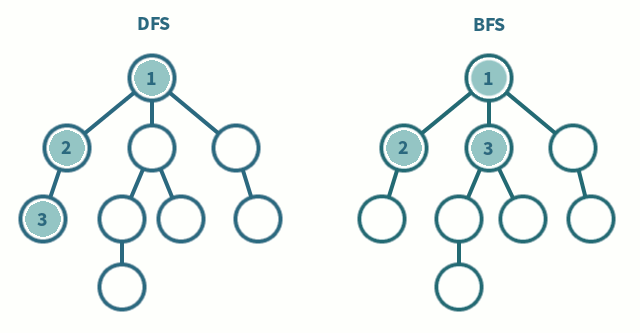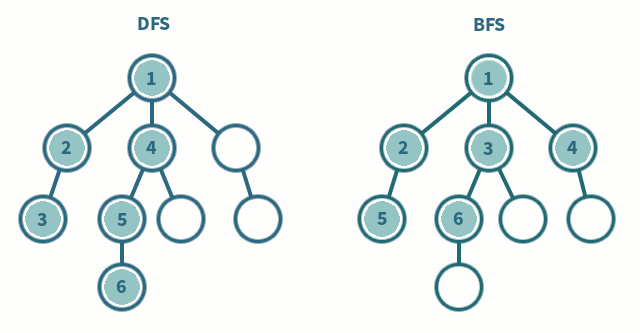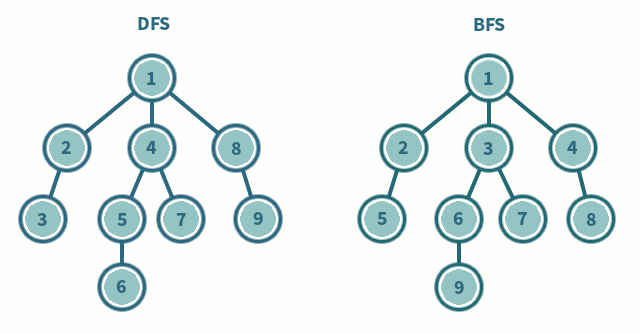
- Zeitkomplexität:
- Speicherkomplexität:
Breitendurchlauf
Verwenden einer Queue (First In, First Out), um die Suche zu organisieren
Ein Knoten wird ausgewählt, dann besucht und als “visited” markiert. Dann kommen die Nachbarknoten in die Queue und werden wiederum ausgewählt, besucht und als “visited” markiert
Ablauf:
- Anfangsknoten zur Queue hinzufügen
- Anfangsknoten von der Queue pullen
- Anfangsknoten wurde noch nicht gesehen => Als “Gesehen” markieren
- Anfangsknoten bearbeiten
- Ungesehene Nachbarknoten zur Queue hinzufügen
- Erstes Element der Queue (welches als erstes eingefügt wurde) von der Queue pullen
- Wenn der Nachbarknoten noch nicht gesehen wurde => Als “Gesehen” markieren, sonst weiter zu Schritt 6
Tiefendurchlauf
Verwenden eines Stack (First In, Last Out), um die Suche zu organisieren
Zeitstempel der ersten Prüfung des Knotens
Zeitstempel, an der der Algorithmus mit Knoten fertig ist
Vorgänger von in der Suche
Laufzeit:
Die Kanten heißen Baumkanten und bilden einen Wald (Tiefenwald)
Nach DFS ist jedem Knoten ein Intervall zugeordnet
Wenn , dann ist eine "ab"-Kante
Wenn , dann ist eine "auf"-Kante
In einem DAG gibt es keine "auf"-Kanten
Wenn , dann ist eine "rückwärts"-Kante
Der Fall einer "vorwärts"-Kante kann nicht auftreten (wegen Tiefensuche)
Ablauf:
- Anfangsknoten zum Stack hinzufügen
- Anfangsknoten vom Stack poppen
- Anfangsknoten wurde noch nicht gesehen => Als “Gesehen” markieren
- Anfangsknoten bearbeiten
- Ungesehene Nachbarknoten zum Stack hinzufügen
- Ersten Nachbarknoten (Top of the Stack) vom Stack poppen
- Wenn der Nachbarknoten noch nicht gesehen wurde => Als “Gesehen” markieren, sonst weiter zu Schritt 6
- ...
Topologisches Sortieren
Nur möglich, wenn der Graph keine Zyklen enthält (nur bei DAGs)
Laufzeit:
Jeder Baum kann topologisch Sortiert werden (erst alle Knoten von k, dann k-1, ... bis zur Wurzel rückwerts in die Liste einfügen)
Oftmals gibt es mehrere Möglichkeiten eine topologische Sortierung zu erstellen
Anschaulich: Alle Kanten "zeigen nach rechts"
Idee zum Algorithmus (alternativer Algorithmus über DFS)
- Knoten ohne Vorgänger können direkt abgearbeitet werden
- Falls Knoten abgearbeitet wurde, verringert sich für alle seine Nachfolger die Anzahl deren Vorgänger um 1
- falls für einen Knoten die Vorgängeranzahl 0 erreicht, kann auch dieser ausgegeben werden
Graph Isomorphismus Probelm
- Bis heute ungelöst, unklar welche Komplexitätsklasse
- Bei einem Isomorphismus gibt es Invarianten, d.h. Größen, die bei den isomorphen Graphen übereinstimmen. Zum Beispiel: Anzahl der Ecken, Anzahl der Kanten, ”Verteilung“ der Eckengrade. Stimmen zwei Graphen nicht in allen diesen Größen überein, können sie nicht isomorph sein

| Linker Graph | Rechter Graph | |
|---|---|---|
| Anzahl Knoten | 6 | 6 |
| Anzahl Kanten | 8 | 8 |
| Anzahl Knoten mit 2 Kanten | 2 | 2 |
| Anzahl Knoten mit 3 Kanten | 4 | 4 |
| Zyklen der Länge 3 | 0 | 6 |
- Ein Isomorphismus muss immer bijektiv sein

Kosaraju’s Algorithmus
Starke Zusammenhangskomponenten (SCC): Zwei Knoten gehören genau dann zu einer solchen Komponente, wenn man zwischen ihnen hin und her gehen kann
Doppelter DFS zur Identifikation der SCC
- Mit niedrigstem Knoten beginnen und immer den niedrigeren Nachbar nehmen
- Anfangs und Enzeiten pro Knoten notieren
- Graph invertieren
- Knotenreihenfolge absteigend nach Endzeit auflisten
- DFS auf invertiertem Graphen in der Knotenreihenfogle abarbeiten
Laufzeit:
Bellman-Ford Algorithmus
Single Source Shortest Path
Kann mit negativen Kantengewichten umgehen
Ablauf
- Distanz zu jedem Knoten auf unendlich setzen
- Startknoten wählen und Distanz zu diesem Knoten auf setzen
- Prüfen: Sind die Kosten zum Ausgangsknoten plus die Kosten der Kante geringer als die bisher bekannten Kosten zum Zielknoten? Wenn ja, dann wird die Distanz aktualisiert und der aktuelle Vorgänger notiert
- mal die Kanten prüfen
- Zuletzt noch eine Prüfung: Entsteht noch ein kürzerer Weg, dann enthält der Graph einen Zyklus mit negativem Gewicht und bricht ab
Laufzeit:
- Zu Beginn wird jedem Knoten der Wert ∞ zugewiesen. Dafür benötigen wir Schritte
- Dann führen wir die Phasen des Algorithmus durch - eine Phase weniger als die Anzahl der Knoten. In jeder Phase werden alle Kanten des Graphen überprüft, und der Abstandswert des Zielknotens kann geändert werden. Wir können diese Überprüfung und Zuweisung eines neuen Wertes als einen Schritt interpretieren und haben somit m Schritte in jeder Phase. In Summe benötigen alle Phasen zusammen Schritte
- Anschließend prüft der Algorithmus, ob ein negativer Kreis vorhanden ist, wofür er jede Kante einmal betrachtet. Insgesamt benötigt er Schritte für die Prüfung
- Laufzeit Gesamt:
Bellman-Ford's Algorithmus und Dijkstra's Algorithmus sind in ihrer Struktur sehr ähnlich. Während Dijkstra nur die unmittelbaren Nachbarn eines Vertexes betrachtet, geht Bellman in jeder Iteration jede Kante durch.
Dijkstra Algorithmus
Bei Dijkstra wird jede Kante nur einmal relaxiert
Ablauf
Weg zum Startknoten hat Kosten , alle andere haben Kosten ∞
- Startknoten in Warteschlange einfügen
- Vorderster Knoten wird aus Warteschlange enttnomen
- Nachbarknoten werden betrachtet
Ist der Knoten in der Warteschlange enthalten und sind die Kosten über die neue Kante geringer als die bisherigen Kosten?
- Ja? Dann werde die Kosten für diesen Knoten auf den neuen Wert verringert
- Nein? Ist der Knoten bisher noch gar nicht besucht worden? Falls ja, wird er nun in die Warteschlange eingefügt, damit später auch die Kanten, die von ihm aus weggehen, betrachtet werden können. Außerdem erhält dieser Knoten die Kosten, die sich aus der Summe der Kosten zu seinem Vorgängerknoten und den Kosten der neuentdeckten Kante zu ihm selbst ergeben.
Laufzeit:
- Da jeder Knoten des Graphen betrachtet wird, brauchen wir mindestens Schritte.
- Um einen Knoten zu behandeln, muss er zuerst aus der Warteschlange entnommen werden. Da wir jedoch immer nur den Knoten, der momentan die geringste Distanz zum Startknoten hat, entnehmen, kann man sich die Warteschlange so vorstellen, dass aus allen n Knoten derjenige mit der geringsten Distanz gesucht wird. Um die Knoten auszuwählen braucht der Algorithmus also Einzelschritte. Bei Hollow Heaps braucht
DeleteMinnur Zeit, also insgesamt - Um neue Knoten in die Warteschlange einzufügen, werden die Nachbarknoten der ausgehenden Kanten dieses Knotens betrachtet und anhand des Gewichts entschieden, ob der Nachbarknoten in die Warteschlange eingereiht wird oder nicht. Somit werden alle erreichbaren Kanten betrachtet, was bedeutet, dass der Algortihmus weitere Einzelschritte benötigt.
- Insgesamt liegt die Laufzeit des Algortihmus also in der Größenordnung , wenn man die Warteschlange als Liste von Knoten betrachtet
- Bei Einsatz einer Heap Struktur für Warteschlange auch möglich
Johnson’s APSP Algorithm
Benutzt Bellman Ford um negative Kantengewichte in positive Umzuwandeln und Dijkstra um die kürzesten Wege zu finden
Ablauf:
- Dem Graphen wird ein neuer Knoten hinzugefügt. Jeder Knoten in wird mit verbunden
- Es werden mit Hilfe des Bellman Ford Algorithmus die kürzesten Wege von zu jedem Knoten berechnet und in
h[]gespeichert - wird entfernt und die ursprünglichen Kanten werden anhand der Formel neu gewichtet
- Dijkstra für jeden Knoten als source ausführen
Zeitkomplexität:
- Einmal Bellman Ford:
- mal Dijkstra:
- Insgesamt:
Floyd-Warshall Algorithmus
Versucht sukzessive, zwei Knoten über einen Zwischenknoten günstiger zu verbinden als bisher
Ablauf:
- Initialisierung der Kostenadjazenz- und Wegeadjazenzmatrix
- Für jedes Knotenpaar und jedes (Shortcut) werden die Kosten berechnet
- Minimale Werte werden gespeichert
Laufzeit:
Minimale Spannbäume
Grundlagen
- Spannbaum: kreisfreier Subgraph, der alle Knoten verbindet
- Der Spannbaum mit dem geringsten Gewicht wird minimaler Spannbaum (MST) genannt
- Jeder ungerichtete Graph hat einen minimalen Spannwald (MSF), das heißt eine Menge von minimalen Spannbäumen (für jede zusammenhängende Komponente einer)
Kruskal Algorithmus
Der Algorithmus wird mit einem Wald, welcher aus Bäumen mit einzelnen Knoten besteht, initialisiert
Die Kanten werden ihrem Gewicht nach in einer Warteschlange sortiert
In jeder Iteration wird eine Kante aus der Warteschlange entfernt
- Falls die Endpunkte der Kante zu verschiedenen Bäumen gehören, werden diese über die Kante vereinigt
- Falls die Endpunkte der Kante zum gleichen Baum gehört, wird die Kante ignoriert
Dies wird so lange wiederholt, bis alle Knoten zum selben Baum gehören oder keine Kanten mehr in der Warteschlange sind
Laufzeit:
- Sortieren der Kanten in
- Da , ist die Zeit maximal
- Union Operation ist maximal
Prim Algorithmus
Der Algorithmus beginnt den Baum mit einem beliebigen einzelnen Knoten, und fügt dann in jeder Iteration eine Kante hinzu
Diese hinzugefügte Kante hat unter allen Kanten, welche den Baum mit Knoten außerhalb des Baums verbinden, minimales Gewicht
Dieser Vorgang wird so lange wiederholt, bis alle Knoten im Baum sind.
Die effizienteste Implementierung des Algorithmus erfolgt über eine Warteschlange. Diese Warteschlange speichert alle Knoten, welche schon besucht wurden, aber noch nicht in den Baum eingefügt sind
Die Reihenfolge der Knoten in der Warteschlange wird über die Distanz jedes Knoten zum Baum bestimmt. In jeder Iteration wird also der Knoten, welcher über die billigste Kante mit dem Baum verbunden ist, aus der Warteschlange entfernt.
Laufzeit:
- In jeder Iteration wird der Knoten an erster Position der Warteschlange entfernt und alle seine Nachbarn betrachtet
- Das Update der Distanzwerte der Nachbarn und die Auswahl des Knoten mit der kleinsten Distanz benötigt Schritte. Falls die Warteschlange also als einfache Liste implementiert ist, benötigt der Algorithmus Schritte (Hollow Heap: )
Übungen
Laufzeiten bestimmen
Beweise:
- Angenommen ist wahr
- Dann existiert und ein , so dass für alle gilt:
- Der Grenzwert von existiert mit
- Widerspruch: Da , existiert kein
Beweise:
Beweise:
Induktion über mit
Beweis:
- Bei und
Beweis:
- Bei und
Beweise:
Da
- die Funktionen und differenzierbar sind
- und
- kann die Regeln von l'Hospital angewendet werden
Anzahl der Funktionsaufrufe
xxxxxxxxxxi = n;while (i > 1) do for j in range(1,i) f(j); i = i/3ist die Anzahl der Aufrufe der Funktion
für alle , da bereits im ersten Durchlauf die inneren for-Schleife -mal durchlaufen wird
Master Theorem:
Da , wird der erste Fall angewendt und damit ist
wir -mal aufgerufen, jeder Aufruf hat Laufzeit. Insgesamt also
Wie kann man den Katasube-Ofman Algorithmus verallgemeinern?
- =
- =
- =
Wurf mit Bällen auf Eimer
- Es sei D die erwartet Anzahl von Bällen, die geworfen werden, bis irgendein Eimer zwei Bälle enthält
- Annahme: die ersten Bälle landen alle in verschiedenen Eimern. In diesem Fall wird die zu erwartende Anzahl an Würfen offensichtlich nicht kleiner als D sein
- E ist die Anzahl der Würfe, die notwendig sind, ehe ein weiterer Ball in einem dieser Eimer landet
- Für jeden neuen Wurf, nach den ersten wird mit einer Wahrscheinlichkeit von einer der ersten Eimer getroffen. Andersherum wir mit einer Wahrscheinlichkeit von ein leerer Eimer getroffen
- Zusammen mit den initialen Würfen erhalten wir
Dijkstra mit negativen Kanten
- Sobald ein Knoten als „fertig" markiert ist - der Algorithmus den kürzesten Pfad zu ihm gefunden hat, und diesen Knoten nie wieder untersuchen muss - nimmt er an, dass der zu diesem Pfad untersuchte Pfad der kürzeste ist.
- Aber mit negativen Gewichten - muss das nicht wahr sein
- Wenn wir einen Knoten offen haben, dass seine Kosten minimal sind - durch Hinzufügen einer beliebigen positiven Zahl zu einem beliebigen Knoten - wird sich die Minimalität nie ändern.
- Ohne die Einschränkung auf positive Zahlen - ist die obige Annahme nicht wahr
- Der Dijkstra-Algorithmus versucht nicht, einen kürzeren Pfad zu bereits aus Q extrahierten Knoten zu finden.
Pseudocode
Sorting Algorithms
Insertion Sort
xxxxxxxxxxfunction insertionSort(inputArr) { let n = inputArr.length; for (let i = 1; i < n; i++) { // Choosing the first element in our unsorted subarray let current = inputArr[i]; // The last element of our sorted subarray let j = i-1; while ((j > -1) && (current < inputArr[j])) { inputArr[j+1] = inputArr[j]; j--; } inputArr[j+1] = current; } return inputArr;}xxxxxxxxxxmark first element as sortedfor each unsorted element X'extract' the element Xfor j = lastSortedIndex down to 0if current element j > Xmove sorted element to the right by 1break loop and insert X here
Selection Sort
xxxxxxxxxxfunction selectionSort(inputArr) { let n = inputArr.length; for(let i = 0; i < n; i++) { // Finding the smallest number in the subarray let min = i; for(let j = i+1; j < n; j++){ if(inputArr[j] < inputArr[min]) { min=j; } } if (min != i) { // Swapping the elements let tmp = inputArr[i]; inputArr[i] = inputArr[min]; inputArr[min] = tmp; } } return inputArr;}xxxxxxxxxxrepeat (numOfElements - 1) timesset the first unsorted element as the minimumfor each of the unsorted elementsif element < currentMinimumset element as new minimumswap minimum with first unsorted position
Merge Sort
xxxxxxxxxxfunction mergeSort(array) { const half = array.length / 2 // Base case or terminating case if(array.length < 2){ return array } const left = array.splice(0, half) return merge(mergeSort(left),mergeSort(array))}function merge(left, right) { let arr = [] // Break out of loop if any one of the array gets empty while (left.length && right.length) { // Pick the smaller among the smallest element of left and right sub arrays if (left[0] < right[0]) { arr.push(left.shift()) } else { arr.push(right.shift()) } } // Concatenating the leftover elements // (in case we didn't go through the entire left or right array) return [ arr, left, right ]}xxxxxxxxxxsplit each element into partitions of size 1recursively merge adjacent partitionsfor i = leftPartIdx to rightPartIdxif leftPartHeadValue <= rightPartHeadValuecopy leftPartHeadValueelse: copy rightPartHeadValuecopy elements back to original array
Quick Sort
xxxxxxxxxxfunction quickSortRecursive(arr, start, end) { // Base case or terminating case if (start >= end) { return; } // Returns pivotIndex let index = partition(arr, start, end); // Recursively apply the same logic to the left and right subarrays quickSort(arr, start, index - 1); quickSort(arr, index + 1, end);}function partition(arr, start, end){ // Taking the last element as the pivot const pivotValue = arr[end]; let pivotIndex = start; for (let i = start; i < end; i++) { if (arr[i] < pivotValue) { // Swapping elements [arr[i], arr[pivotIndex]] = [arr[pivotIndex], arr[i]]; // Moving to next element pivotIndex++; } } // Putting the pivot value in the middle [arr[pivotIndex], arr[end]] = [arr[end], arr[pivotIndex]] return pivotIndex;};xxxxxxxxxxfor each (unsorted) partitionrandomly select pivot, swap with first elementstoreIndex = pivotIndex + 1for i = pivotIndex + 1 to rightmostIndexif element[i] < element[pivot]swap(i, storeIndex); storeIndex++swap(pivot, storeIndex - 1)
Heap Sort
xxxxxxxxxxfunction heapSort(a){ let n = a.length; for(let i=Math.floor(n/2)-1;i>=0;i--){ max_heapify(a,i,n); //Building max heap } for(let i = n-1;i>=0;i--){ swap(a,0,i); //Deleting root element max_heapify(a,0,i); //Building max heap again } return a;}function max_heapify(a,i,n){ let left = 2*i; //Left child index let right = 2*i+1; //Right child index let maximum; if(right<n){ //Checks if right child exist if(a[left]>=a[right]){ //Compares children to find maximum maximum = left; } else{ maximum = right; } } else if(left<n){ //Checks if left child exists maximum = left; } else return; //In case of no children return if(a[i]<a[maximum]){ //Checks if the largest child is greater than parent swap(a,i,maximum); //If it is then swap both max_heapify(a,maximum,n); //max-heapify again } return;}Counting Sort
xxxxxxxxxxlet countingSort = (arr, min, max) => { let i = min, j = 0, len = arr.length, count = []; for (i; i <= max; i++) { count[i] = 0; } for (i = 0; i < len; i++) { count[arr[i]] += 1; } for (i = min; i <= max; i++) { while (count[i] > 0) { arr[j] = i; j++; count[i]--; } } return arr;};xxxxxxxxxxcreate key (counting) arrayfor each element in listincrease the respective counter by 1for each counter, starting from smallest keywhile counter is non-zerorestore element to listdecrease counter by 1
Radix Sort
xxxxxxxxxxfunction radixSort(arr) { const max = getMax(arr); // length of the max digit in the array for (let i = 0; i < max; i++) { let buckets = Array.from({ length: 10 }, () => [ ]) for (let j = 0; j < arr.length; j++) { buckets[getPosition(arr[ j ], i)].push(arr[ j ]); // pushing into buckets } arr = [ ].concat(buckets); } return arr}function getMax(arr) { let max = 0; for (let num of arr) { if (max < num.toString().length) { max = num.toString().length } } return max}function getPosition(num, place){ return Math.floor(Math.abs(num)/Math.pow(10,place))% 10}Datenstrukturen
Verkettete Liste
xxxxxxxxxxfunction search(v) { if empty, return NOT_FOUND index = 0, temp = head while (temp.item != v) index++, temp = temp.next if temp == null return NOT_FOUND return index}function insert_head(v) { Vertex vtx = new Vertex(v) vtx.next = head head = vtx}function delete_tail() { if empty, return Vertex pre = head temp = head.next while (temp.next != null) pre = pre.next pre.next = null delete temp, tail = pre}Doppelt verkettete Liste
xxxxxxxxxxfunction delete_item(i) { if empty, return Vertex pre = head for (k = 0; k < i-1; k++) pre = pre.next Vertex del = pre.next, aft = del.next pre.next = aft, aft.prev = pre delete del}function delete_tail() { if empty, return temp = tailtail = tail.prevtail.next = nulldelete temp}Stack
xxxxxxxxxxfunction push(v) { Vertex vtx = new Vertex(v) vtx.next = head head = vtx}function pop() { if empty, return temp = head head = head.next delete temp}Queue
xxxxxxxxxxfunction enqueue(v) { Vertex vtx = new Vertex(v) tail.next = vtx tail = vtx}function dequeue() { if empty, return temp = head head = head.next delete temp}Binärer Heap
xxxxxxxxxxfunction build_heap(arr) { for (i = arr.length/2; i >= 1; i--) shiftDown(i)}function insert_into_heap(v) { A[A.length] = v i = A.length-1 while (i > 1 && A[parent(i)] < A[i]) swap(A[i], A[parent(i)])}function extract_max() { take out A[1] A[1] = A[A.length-1] i = 1; A.length-- while (i < A.length) if A[i] < (L = the larger of i's children) swap(A[i], L)}Graphen
Topologisches Sortieren
xxxxxxxxxxfunction TopoSort(DAG) { S = empty // Menge der abgearbeiteten Knoten for (i=0, i<n, i++) { P[i] = Anzahl Vorgänger des Knoten i } while V \ S not empty { wähle w aus V \ S mit P[w]==0; gib w aus; S = S ohne {w}; für jeden Nachfolger v von w { --P[v]; } }}DFS
xxxxxxxxxxDFS-iterative (G, s): let S be stack S.push( s ) //Inserting s in stack mark s as visited. while ( S is not empty): //Pop a vertex from stack to visit next v = S.top( ) S.pop( ) //Push all the neighbours of v in stack that are not visited for all neighbours w of v in Graph G: if w is not visited : S.push( w ) mark w as visitedBFS
xxxxxxxxxxBFS (G, s) let Q be queue. Q.enqueue( s ) //Inserting s in queue until all its neighbours are marked. mark s as visited. while ( Q is not empty) //Removing that vertex from queue,whose neighbour will be visited now v = Q.dequeue( ) //processing all the neighbours of v for all neighbours w of v in Graph G if w is not visited Q.enqueue( w ) //Stores w in Q to further visit its neighbour mark w as visited.
Bellman-Ford
xxxxxxxxxxfor v in V: v.distance = infinity v.p = Nonesource.distance = 0for i from 1 to |V| - 1: for (u, v) in E: relax(u, v)for (u, v) in E: if v.distance > u.distance + weight(u, v): print "A negative weight cycle exists"relax(u, v): if v.distance > u.distance + weight(u, v): v.distance = u.distance + weight(u, v) v.p = uDijkstra
xxxxxxxxxxfunction Dijkstra(G,s) for earch v in G: v.distance = infinity v.p = None source.distance = 0 Q = set of all nodes in G while Q is not empty u = node in Q with smallest distance remove u from Q for each neighbor v of u: alt = u.distance + weight(u,v) if alt < v.distance v.distance = alt v.p = u return previous[]Kruskal
xxxxxxxxxxfunction kruskal(G,s) T = empty Q = sortiere E nach w(u,v) for V in G make-tree(V) while Q is not empty AND trees-count > 1 {u,v} = Q.extractMin() if T with {u,v} does not contain loop T.add({u,v}) merge(tree-of(u),tree-of(v))Prim
xxxxxxxxxxfunction prim(G,s) T = empty for i in range (1,n) d(V[1]) = infinity parent(v[i]) = null d(s) = 0 queue = V while Q is not empty u = Q.extractMin() for all neighbors of u in G if neighbor in queue AND w({u,neighbor}) < d[neighbor] Q.decreaseKey() parent[neighbor] = u